
你好,我是王喆。从今天开始,我们正式开始学习“深度学习推荐系统”了。在开始之前,我想先问你一个问题:当你开始学习一个全新领域的时候,你想做的第一件事情是什么?
当然每个人可能都有自己的答案,但对于我自己来说,我最想搞明白的是两个问题。一个是,这个领域到底要解决什么问题?第二个是,这个领域有没有一个非常高角度的思维导图,让我能够了解这个领域有哪些主要的技术,做到心中有数?
针对“深度学习推荐系统”这个领域啊,可能还会有第三个问题,为什么我们要一直强调“深度学习”,深度学习到底给推荐系统带来了什么革命性的影响?相信听完了这一节课,你心中的这三个问题也都能迎刃而解。
## 推荐系统要解决的根本问题是什么?
在开篇词中我们提到,推荐系统的应用已经渗透到购物、娱乐、学习等生活的方方面面,虽然商品推荐、视频推荐、新闻推荐这些推荐场景可能完全不同,既然它们都被称为“推荐系统”,解决的本质问题一定是相通的,遵循着共通的逻辑框架。
推荐系统要解决的问题用一句话总结就是,在“信息过载”的情况下,用户如何高效获取感兴趣的信息。
因此,推荐系统正是在“浩如烟海的互联网信息”和“用户的兴趣点”之间,搭建起的一座桥梁。那这座桥是怎么一步步搭建起来的呢?下面,我们先来看看,推荐系统比较抽象的逻辑架构是什么样的,再一步步搭建起它的技术架构,让你对推荐系统有一个整体上的印象。
## 推荐系统的逻辑架构
从推荐系统的根本问题出发,我们可以清楚地知道,推荐系统要处理的其实是“人”和“信息”之间的关系问题。也就是基于“人”和“信息”,构建出一个找寻感兴趣信息的方法。
这里“信息”的定义非常多样,它在不同场景下的具体含义也千差万别。比如说,在商品推荐中指的是“商品信息”,在视频推荐中指的是“视频信息”,在新闻推荐中指的是“新闻信息”,为了方便,我们可以把它们统称为“物品信息”。
而从“人”的角度出发,为了更可靠地推测出“人”的兴趣点,推荐系统希望能利用大量与“人”相关的信息,这类信息包括历史行为、人口属性、关系网络等,它们可以被统称为“用户信息”。
此外,在具体的推荐场景中,用户的最终选择一般会受时间、地点、用户的状态等一系列环境信息的影响,这些环境信息又可以被称为“场景信息”或“上下文信息”。
清楚了这些信息的定义,推荐系统要处理的问题就可以被形式化地定义为:对于某个用户U*(User),在特定场景C*(Context)下,针对海量的“物品”信息构建一个函数 ,预测用户对特定候选物品I*(Item)的喜好程度,再根据喜好程度对所有候选物品进行排序,生成推荐列表的问题*。
这样一来,我们就可以抽象出推荐系统的逻辑框架了。虽然这个逻辑框架还比较简单,但我们正是在此基础上,对各模块进行细化和扩展,才产生了推荐系统的整个技术体系。
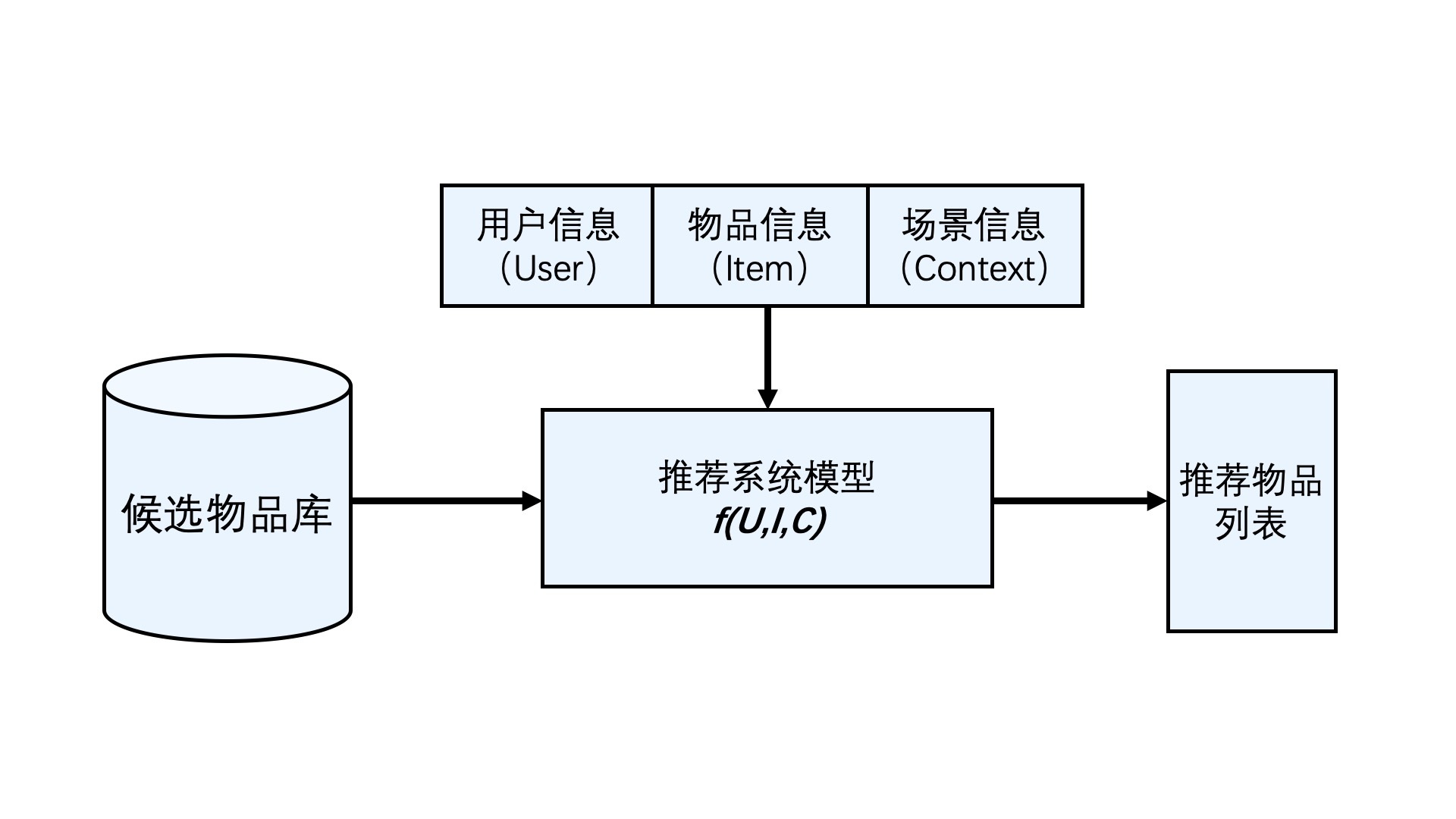
图1 推荐系统逻辑架构
## 深度学习对推荐系统的革命
有了推荐系统的逻辑架构,我就能回答开头的第三个问题“深度学习到底给推荐系统带来了什么革命性的影响?”。
在推荐系统逻辑架构图中,居于中心位置的是一个抽象函数f(U,I,C),它负责“猜测”用户的心,为用户可能感兴趣的物品打分,从而得出最终的推荐物品列表。在推荐系统中,这个函数一般被称为“推荐系统模型”(今后简称“推荐模型”)。
深度学习应用于推荐系统,能够极大地增强推荐模型的拟合能力和表达能力。简单来说,就是让推荐模型“猜的更准”,更能抓住用户的“心”。这么说你可能还没有一个清晰的概念,接下来,我们再从模型结构的角度出发,来比较一下传统机器学习推荐模型和深度学习推荐模型的区别,让你有一个更清晰的认识。
我在下面给出了一张模型结构对比图,它对比了传统的矩阵分解模型和深度学习矩阵分解模型的区别。我们先忽略细节不谈,你第一眼看上去有什么感觉?是不是觉得深度学习模型变得更复杂了,一层又一层,层数增加了很多。
你的感觉一点儿都没错,其实正是因为深度学习复杂的模型结构,让深度学习模型具备了理论上拟合任何函数的能力。如果说f(U,I,C) 这个推荐函数具有一个最优的表达形式,那传统的机器学习模型只能够拟合出f(U,I,C) 这个推荐函数的近似形式,而深度学习模型则可以最大程度地接近这个最优形式。
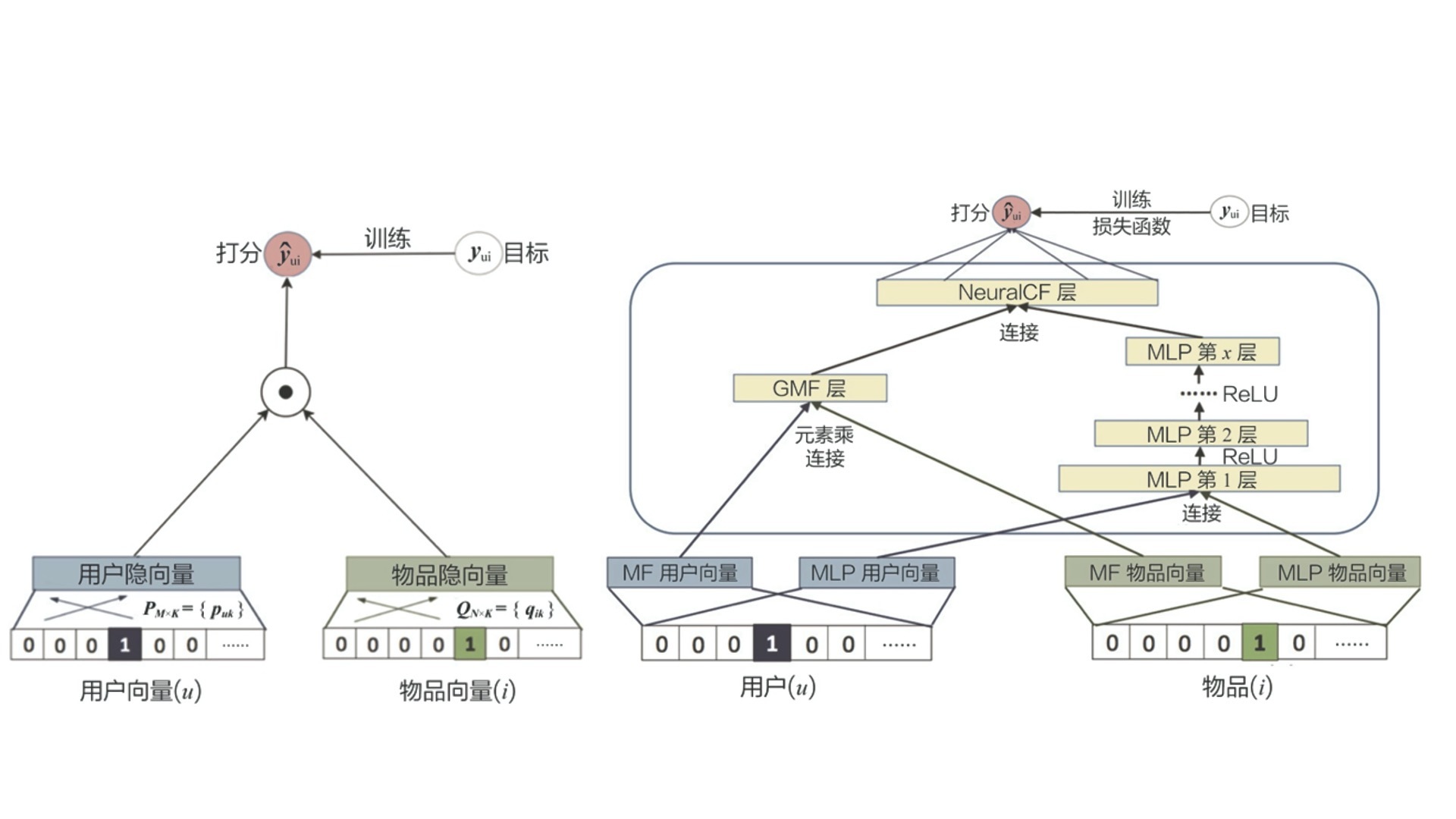
图2 传统的矩阵分解模型和深度学习矩阵分解模型的对比图
来源:《Neural collaborative filtering》
除此之外,深度学习模型非常灵活的模型结构还让它具备了一个无法替代的优势,就是我们可以让深度学习模型的神经网络模拟很多用户兴趣的变迁过程,甚至用户做出决定的思考过程。比如阿里巴巴的深度学习模型——深度兴趣进化网络(如图 3),它利用了三层序列模型的结构,模拟了用户在购买商品时兴趣进化的过程,如此强大的数据拟合能力和对用户行为的理解能力,是传统机器学习模型不具备的。
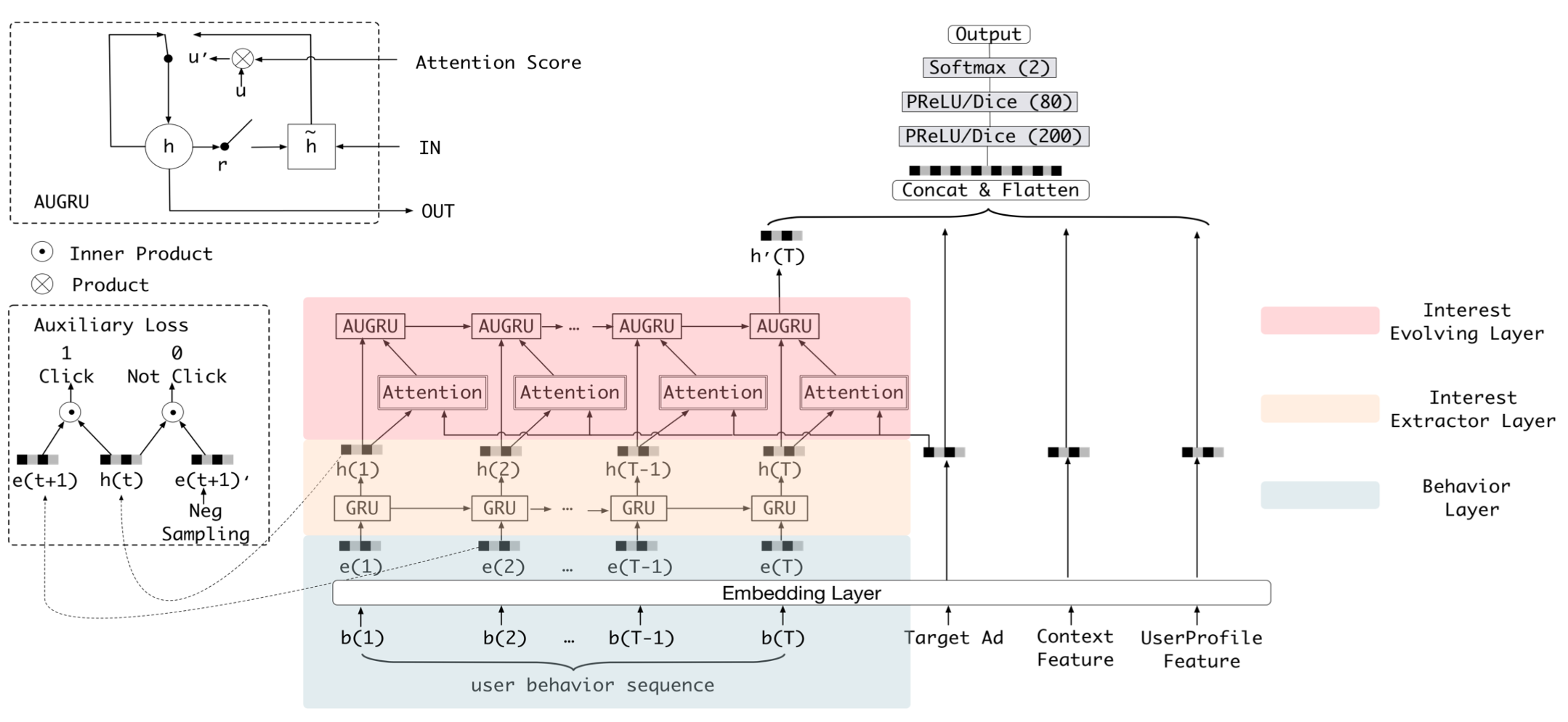
图3 阿里巴巴的深度兴趣进化网络
来源:《Deep Interest Evolution Network for Click-Through Rate Prediction》
但是,深度学习对推荐系统的革命影响还远不止这些。近几年,由于深度学习模型的结构复杂度大大提高,使通过训练使模型收敛所需的数据量大大增加,这也反向推动了推荐系统大数据平台的发展,让推荐系统相关的大数据存储、处理、更新模块也一同迈入了“深度学习时代”。
讲了这么多深度学习对推荐系统的影响,我们似乎还没看到一个完整的深度学习推荐系统架构。别着急,下面,我们就来讲一讲,经典的深度学习推荐系统的技术架构是什么样的。
## 深度学习推荐系统的技术架构
讲之前啊,我还要说明一点,深度学习推荐系统的架构与经典的推荐系统架构其实是一脉相承的,它对经典推荐系统架构中某些特定模块进行了改进,使之能够支持深度学习的应用。所以,我会先讲经典的推荐系统架构,再讲深度学习对它们的改进。
在实际的推荐系统中,工程师需要着重解决的问题有两类。
一类问题与数据和信息相关,即“用户信息”“物品信息”“场景信息”分别是什么?如何存储、更新和处理数据?
另一类问题与推荐系统算法和模型相关,即推荐系统模型如何训练、预测,以及如何达成更好的推荐效果?
一个工业级推荐系统的技术架构其实也是按照这两部分展开的,其中“数据和信息”部分逐渐发展为推荐系统中融合了数据离线批处理、实时流处理的数据流框架;“算法和模型”部分则进一步细化为推荐系统中,集训练(Training)、评估(Evaluation)、部署(Deployment)、线上推断(Online Inference)为一体的模型框架。基于此,我们就能总结出推荐系统的技术架构图。
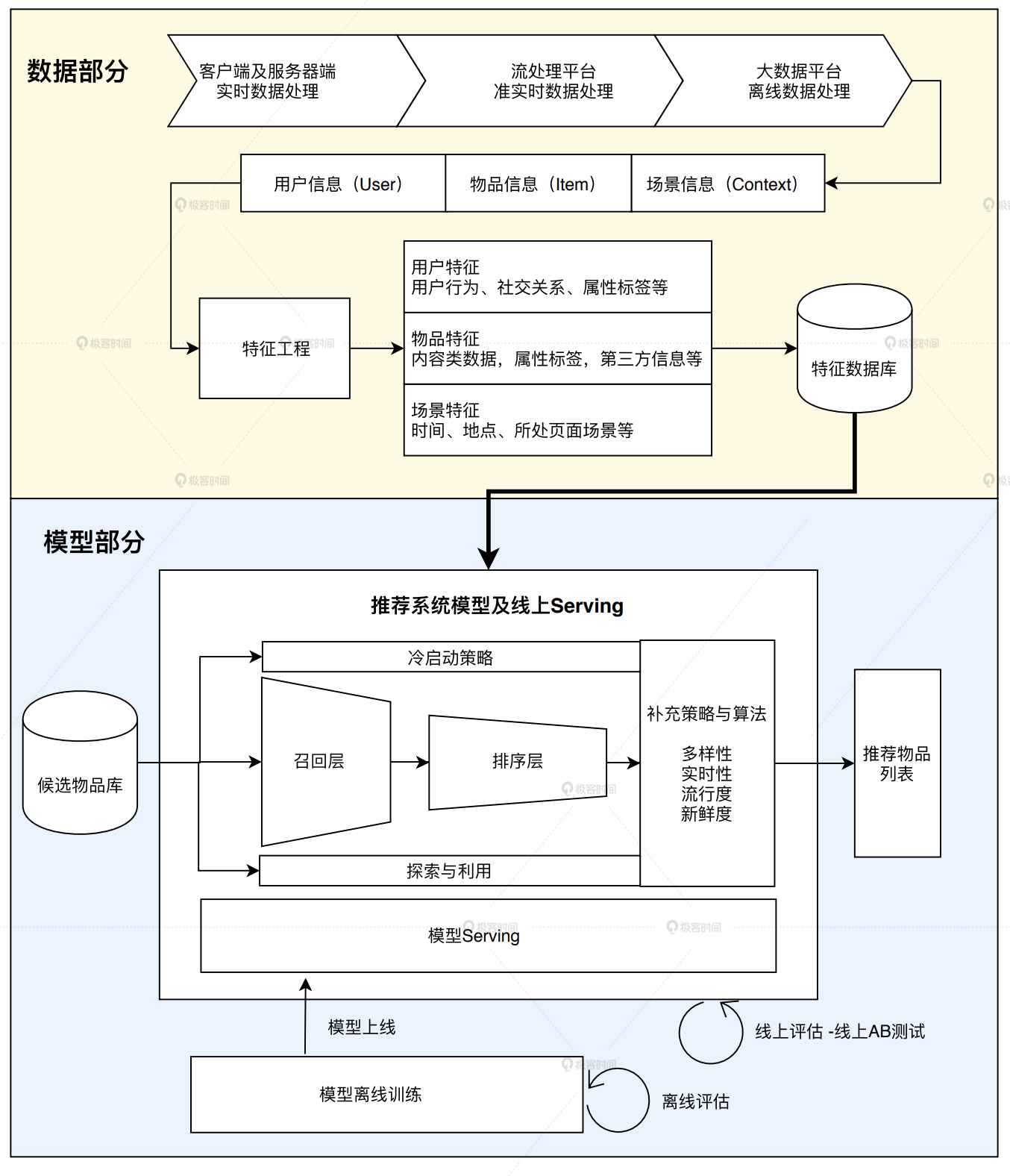
图4 推荐系统技术架构示意图
在图 4 中,我把推荐系统的技术架构分成了“数据部分”和“模型部分”。那它们的工作内容和作用分别是什么呢?深度学习对于这两部分的影响又有哪些呢?下面,我来一一讲解。
### 第一部分:推荐系统的数据部分
推荐系统的“数据部分”主要负责的是“用户”“物品”“场景”信息的收集与处理。根据处理数据量和处理实时性的不同,我们会用到三种不同的数据处理方式,按照实时性的强弱排序的话,它们依次是客户端与服务器端实时数据处理、流处理平台准实时数据处理、大数据平台离线数据处理。
在实时性由强到弱递减的同时,三种平台的海量数据处理能力则由弱到强。因此,一个成熟推荐系统的数据流系统会将三者取长补短,配合使用。我们也会在今后的课程中讲到具体的例子,比如使用 Spark 进行离线数据处理,使用 Flink 进行准实时数据处理等等。
大数据计算平台通过对推荐系统日志,物品和用户的元数据等信息的处理,获得了推荐模型的训练数据、特征数据、统计数据等。那这些数据都有什么用呢?具体说来,大数据平台加工后的数据出口主要有 3 个:
生成推荐系统模型所需的样本数据,用于算法模型的训练和评估。
生成推荐系统模型服务(Model Serving)所需的“用户特征”,“物品特征”和一部分“场景特征”,用于推荐系统的线上推断。
生成系统监控、商业智能(Business Intelligence,BI)系统所需的统计型数据。
可以说,推荐系统的数据部分是整个推荐系统的“水源”,我们只有保证“水源”的持续、纯净,才能不断地“滋养”推荐系统,使其高效地运转并准确地输出。在深度学习时代,深度学习模型对于“水源”的要求更高了,首先是水量要大,只有这样才能保证我们训练出的深度学习模型能够尽快收敛;其次是“水流”要快,让数据能够尽快地流到模型更新训练的模块,这样才能够让模型实时的抓住用户兴趣变化的趋势,这就推动了大数据引擎 Spark,以及流计算平台 Flink 的发展和应用。
### 第二部分:推荐系统的模型部分
推荐系统的“模型部分”是推荐系统的主体。模型的结构一般由“召回层”、“排序层”以及“补充策略与算法层”组成。
其中,“召回层”一般由高效的召回规则、算法或简单的模型组成,这让推荐系统能快速从海量的候选集中召回用户可能感兴趣的物品。“排序层”则是利用排序模型对初筛的候选集进行精排序。而“补充策略与算法层”,也被称为“再排序层”,是在返回给用户推荐列表之前,为兼顾结果的“多样性”“流行度”“新鲜度”等指标,结合一些补充的策略和算法对推荐列表进行一定的调整,最终形成用户可见的推荐列表。
从推荐系统模型接收到所有候选物品集,到最后产生推荐列表,这一过程一般叫做“模型服务过程”。为了生成模型服务过程所需的模型参数,我们需要通过模型训练(Model Training)确定模型结构、结构中不同参数权重的具体数值,以及模型相关算法和策略中的参数取值。
模型的训练方法根据环境的不同,可以分为“离线训练”和“在线更新”两部分。其中,离线训练的特点是可以利用全量样本和特征,使模型逼近全局最优点,而在线更新则可以准实时地“消化”新的数据样本,更快地反应新的数据变化趋势,满足模型实时性的需求。
除此之外,为了评估推荐系统模型的效果,以及模型的迭代优化,推荐系统的模型部分还包括“离线评估”和“线上 A/B 测试”等多种评估模块,用来得出线下和线上评估指标,指导下一步的模型迭代优化。
我们刚才说过,深度学习对于推荐系统的革命集中在模型部分,那具体都有什么呢?我把最典型的深度学习应用总结成了 3 点:
深度学习中 Embedding 技术在召回层的应用。作为深度学习中非常核心的 Embedding 技术,将它应用在推荐系统的召回层中,做相关物品的快速召回,已经是业界非常主流的解决方案了。
不同结构的深度学习模型在排序层的应用。排序层(也称精排层)是影响推荐效果的重中之重,也是深度学习模型大展拳脚的领域。深度学习模型的灵活性高,表达能力强的特点,这让它非常适合于大数据量下的精确排序。深度学习排序模型毫无疑问是业界和学界都在不断加大投入,快速迭代的部分。
增强学习在模型更新、工程模型一体化方向上的应用。增强学习可以说是与深度学习密切相关的另一机器学习领域,它在推荐系统中的应用,让推荐系统可以在实时性层面更上一层楼。
## 小结
这节课,我带你熟悉了深度学习推荐系统的技术架构,虽然涉及的内容非常多,但如果没有记住的话,你也完全不用慌张,只需要在心中留下这个框架的印象就可以了。你完全可以把这节课的内容当作整个课程的技术索引,让它成为属于你自己的一张知识图谱。
形象点来说,你可以把这节课程的内容想象成是一颗知识树,它有根,有干、有枝、有叶,还有花。
其中,推荐系统的根就是推荐系统要解决的根本性问题:在“信息过载”情况下,用户怎么高效获取感兴趣的信息。
而推荐系统的干就是推荐系统的逻辑架构:对于某个用户U(User),在特定场景C(Context)下,针对海量的“物品”构建一个函数 ,预测用户对特定候选物品I(Item)的喜好程度的过程。
枝和叶就是推荐系统的各个技术模块,以及各模块的技术选型。技术模块撑起了推荐系统的技术架构,技术选型又让我们可以在技术架构上实现各种细节,开枝散叶。
最后,深度学习在推荐系统的应用无疑是当前推荐系统技术架构上的明珠,它就像是这颗大树上开出的花,是最精彩的点睛之笔。深度学习的模型结构复杂,数据拟合能力和表达能力更强,能够让推荐模型更好的模拟用户的兴趣变迁过程,甚至是做决定的过程。而深度学习的发展,也推动着推荐系统数据流部分的革命,让它能够更快、更强地处理推荐系统相关的数据。
好了,这节课我们就讲到这里,希望你能牢牢记住深度学习推荐系统的架构,播撒下这一粒种子,然后跟随我后面的课程让它长大成一颗属于你自己的参天大树。
图5 推荐系统的技术架构像树一样生发而出
## 课后思考
下面是 Netflix 的推荐系统的经典架构图,你能结合本节课讲的推荐系统技术架构,说出 Netflix 架构图中哪些是数据部分,哪些是模型部分吗?
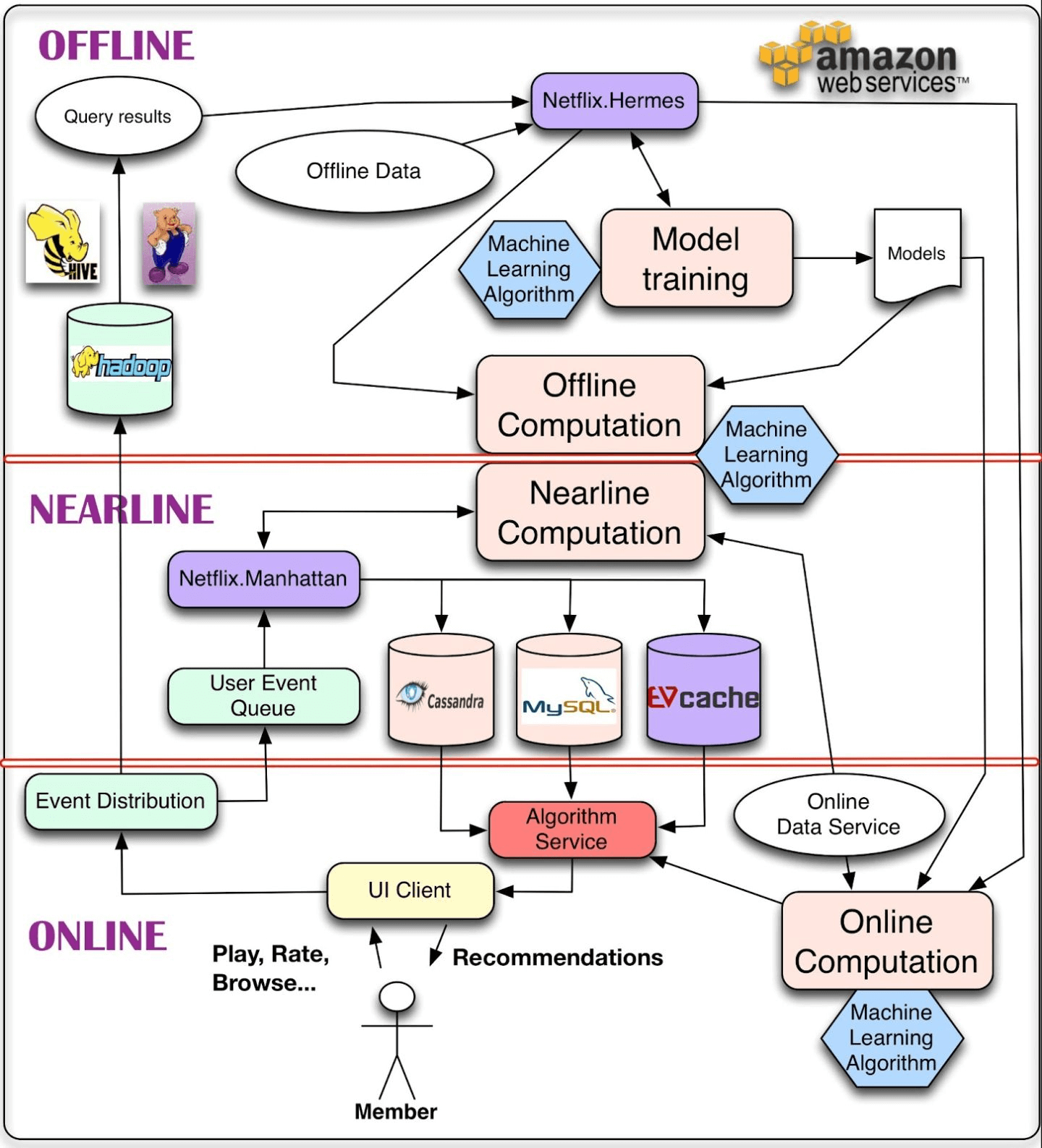
图6 Netflix架构图示意图
这样的深度学习推荐系统和你想的一样吗?如果今天的课程对你有帮助,也欢迎你把它转发出去!我们下节课见!