- 使用预训练的卷积神经网络提取图片中的特征,生成特征向量。
- 利用图片库中所有图片数据构建 <id, feature vector> 数据。
- 使用 Faiss 创建 Index ,利用 <id, feature vector> 数据生成索引。
- 针对待检索图片,使用模型提取图片特征向量,然后使用 Index 检索 TopK 相似图片的 id。
- 可视化检索结果
1. 导包
import os
import time
import torch
import faiss
import numpy as np
import matplotlib.pyplot as plt
from PIL import Image
from torchvision import models, transforms
from torch.utils.data import DataLoader, Dataset
%matplotlib inlineGPU 加速
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(device)
# cuda2.自定义数据集
transform = transforms.Compose([
transforms.Resize((256, 256)),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
class MyDataset(Dataset):
def __init__(self, data_path, transform=None):
super().__init__()
self.transform = transform
self.data_path = data_path
self.data = []
img_path = os.path.join(data_path, 'img.txt')
with open(img_path, 'r', encoding='utf-8') as f:
for line in f.readlines():
line = line.strip()
img_name = os.path.join(data_path, line)
img = Image.open(img_name)
if img.mode == 'RGB':
self.data.append(line)
def __getitem__(self, idx):
# take the data sample by it's index
img_path = os.path.join(self.data_path, self.data[idx])
# read image
img = Image.open(img_path)
# apply the transform
if self.transform:
img = self.transform(img)
# return the image and index
dict_data = {
'index': idx,
'img': img
}
return dict_data
def __len__(self):
return len(self.data)img_folder = 'JPEGImages'
val_dataset = MyDataset(img_folder, transform=transform)
batch_size = 64
val_dataloader = DataLoader(val_dataset, batch_size=batch_size, shuffle=False, num_workers=4)
print('Val_dataset: ', val_dataset.__len__())
print('iter: ', int(val_dataset.__len__()/batch_size)+1)
Val_dataset: 17125
iter: 2683.预训练模型+自定义特征值提取器
# 加载预训练模型
def load_model():
model = models.resnet18(pretrained=True)
model.to(device)
model.eval()
return model
# 定义 特征提取器
def feature_extract(model, x):
x = model.conv1(x)
x = model.bn1(x)
x = model.relu(x)
x = model.maxpool(x)
x = model.layer1(x)
x = model.layer2(x)
x = model.layer3(x)
x = model.layer4(x)
x = model.avgpool(x)
x = torch.flatten(x, 1)
return xmodel = load_model()
for idx, batch in enumerate(val_dataloader):
img = batch['img'] # 图片数据表示 --> 图片特征
index = batch['index']
img = img.to(device)
feature = feature_extract(model, img)
feature = feature.data.cpu().numpy()
imgs_path = [os.path.join(img_folder, val_dataset.data[i] + '.txt') for i in index]
assert len(feature) == len(imgs_path)
for i in range(len(imgs_path)):
feature_list = [str(f) for f in feature[i]]
img_path = imgs_path[i]
with open(img_path, 'w', encoding='utf-8') as f:
f.write(" ".join(feature_list))
print('*' * 60)
print(idx * batch_size)4.图片向量化
# 获取图片特征¶
def img2feat(pic_file):
feat = []
with open(pic_file, 'r', encoding='utf-8') as f:
lines = f.readlines()
feat = [float(f) for f in lines[0].split()]
return featids = []
data = []
img_folder = 'VOC2012'#'VOC2012_small/'
img_path = os.path.join(img_folder,'img.txt')
with open(img_path,'r',encoding='utf-8') as f:
for line in f.readlines():
img_name = line.strip()
img_id = img_name.split('.')[0]
pic_txt_file = os.path.join( img_folder,"{}.txt".format(img_name) )
if not os.path.exists(pic_txt_file):
continue
feat = img2feat(pic_txt_file)
ids.append(int(img_id))
data.append(np.array(feat))
# 构建数据<id,data>
ids = np.array(ids)
data = np.array(data).astype('float32')
d = 512 # feature 特征长度(模型的结果)
print(" 特征向量记录数: ",data.shape)
print(" 特征向量ID的记录数:",ids.shape)
特征向量记录数: (17125, 512)
特征向量ID的记录数: (17125,)5.创建 Faiss 索引 Index
# 创建图片特征索引 - 方案1
# index = faiss.index_factory(d,"IDMap,Flat")
# index.add_with_ids(data,ids)
# 创建图片特征索引-方案2( 资源有限,效果更好 )
###IDMap 支持add_with_ids
###如果很在意,使用”PCARx,...,SQ8“ 如果保存全部原始数据的开销太大,可以用这个索引方式。包含三个部分,
# 1.降维
# 2.聚类
# 3.scalar 量化,每个向量编码为8bit 不支持GPU
index = faiss.index_factory(d, "IDMap,PCAR16,IVF50,SQ8")
index.train(data)
index.add_with_ids(data, ids)
# 索引文件保存磁盘
faiss.write_index(index,'index_file.index') # 讲index保存index_file.index 的文件
# index = faiss.read_index("index_file.index")
# print(index.ntotal) # 查看索引库大小加载 Faiss Index 索引文件
index = faiss.read_index('index_file.index')
print('索引记录数:', index.ntotal)
# 索引记录数: 171256.Faiss 相似 TopK 检索
def index_search(feat,topK ):
"""
feat: 检索的图片特征
topK: 返回最高topK相似的图片
"""
feat = np.expand_dims( np.array(feat),axis=0 )
feat = feat.astype('float32')
start_time = time.time()
dis,ind = index.search( feat,topK )
end_time = time.time()
print( 'index_search consume time:{}ms'.format( int(end_time - start_time) * 1000 ) )
return dis,ind # 距离,相似图片id7.可视化检索结果
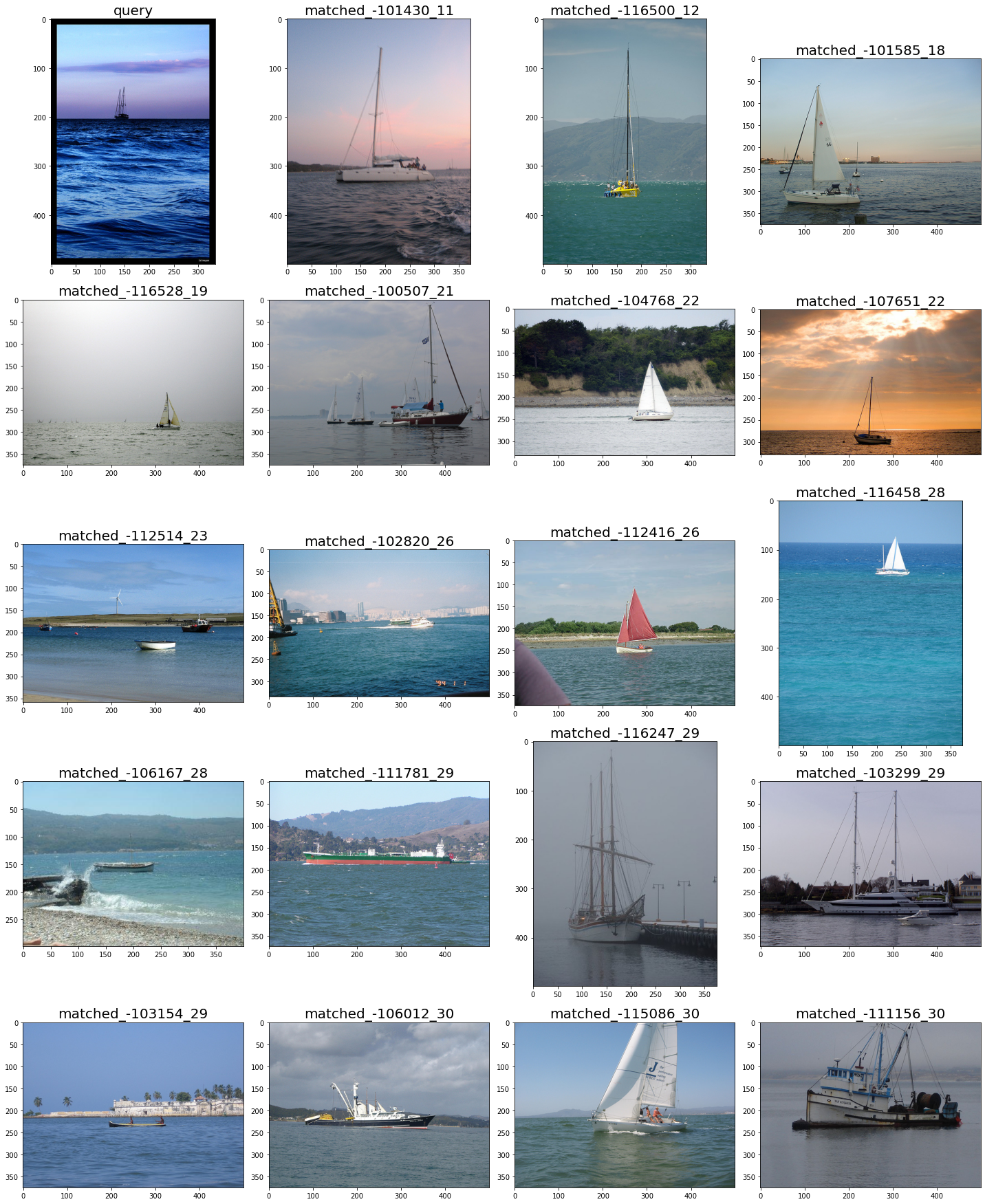
def visual_plot(ind,dis,topK,query_img = None):
# 相似照片
cols = 4
rows = int(topK / cols)
idx = 0
fig,axes = plt.subplots(rows,cols,figsize=(20 ,5*rows),tight_layout=True)
#axes[0,0].imshow(query_img)
for row in range(rows):
for col in range(cols):
_id = ind[0][idx]
_dis = dis[0][idx]
img_path = os.path.join(img_folder,'{}.jpg'.format(_id))
#print(img_path)
if query_img is not None and idx == 0:
axes[row,col].imshow(query_img)
axes[row,col].set_title( 'query',fontsize = 20 )
else:
img = plt.imread( img_path )
axes[row,col].imshow(img)
axes[row,col].set_title( 'matched_-{}_{}'.format(_id,int(_dis)) ,fontsize = 20 )
idx+=1
plt.savefig('pic')img_folder = 'VOC2012/'
# img_id = '100211.jpg'
img_id = '100002.jpg'
topK = 20
img_path = os.path.join( img_folder,img_id)
print(img_path) # 查看 这个img_path 的相似图片
img = Image.open(img_path)
img = transform(img) # torch.Size([3, 224, 224])
img = img.unsqueeze(0) # torch.Size([1, 3, 224, 224])
img = img.to(device)
# 对我们的图片进行预测
with torch.no_grad():
# 图片-> 图片特征
print('1.图片特征提取')
feature = feature_extract( model,img )
# 特征-> 检索
feature_list = feature.data.cpu().tolist()[0]
print('2.基于特征的检索,从faiss获取相似度图片')
# 相似图片可视化
dis,ind = index_search( feature_list,topK=topK )
print('ind = ',ind)
print('3.图片可视化展示')
# 当前图片
query_img = plt.imread( img_path )
visual_plot( ind,dis,topK,query_img)
VOC2012/100002.jpg
1.图片特征提取
2.基于特征的检索,从faiss获取相似度图片
index_search consume time:0ms
ind = [[100002 101430 116500 101585 116528 100507 104768 107651 112514 102820
112416 116458 106167 111781 116247 103299 103154 106012 115086 111156]]
3.图片可视化展示